
Ruby on Rails makes developing modern applications for the web easier. It provides you with almost everything you will need. One of the most important features given to you is the ability to create routes. Routes allow you to direct (or route) a specific page to a path or Uniform Resource Identifier (URI) which basically defines where a page can be found. [1] Due to the nature of Rails, once you create a route it will generate patters for those routes. Using the command rails routes displays all routes for the current application.
Let's learn a bit about a Rails application!
The Structure
Assuming you have Rails, run:
rails new sample_app
This will create a new Rails application with a default directory structure contained in ./sample_app as specified in the above command.
Let us take a look at what it provides:
.
└── sample_app
├── app
│ ├── assets
│ │ ├── config
│ │ │ └── manifest.js
│ │ ├── images
│ │ ├── javascripts
│ │ │ ├── application.js
│ │ │ ├── cable.js
│ │ │ └── channels
│ │ └── stylesheets
│ │ └── application.css
│ ├── channels
│ │ └── application_cable
│ │ ├── channel.rb
│ │ └── connection.rb
│ ├── controllers
│ │ ├── application_controller.rb
│ │ └── concerns
│ ├── helpers
│ │ └── application_helper.rb
│ ├── jobs
│ │ └── application_job.rb
│ ├── mailers
│ │ └── application_mailer.rb
│ ├── models
│ │ ├── application_record.rb
│ │ └── concerns
│ └── views
│ └── layouts
│ ├── application.html.erb
│ ├── mailer.html.erb
│ └── mailer.text.erb
├── bin
│ ├── bundle
│ ├── rails
│ ├── rake
│ ├── setup
│ ├── spring
│ ├── update
│ └── yarn
├── config
│ ├── application.rb
│ ├── boot.rb
│ ├── cable.yml
│ ├── credentials.yml.enc
│ ├── database.yml
│ ├── environment.rb
│ ├── environments
│ │ ├── development.rb
│ │ ├── production.rb
│ │ └── test.rb
│ ├── initializers
│ │ ├── application_controller_renderer.rb
│ │ ├── assets.rb
│ │ ├── backtrace_silencers.rb
│ │ ├── content_security_policy.rb
│ │ ├── cookies_serializer.rb
│ │ ├── filter_parameter_logging.rb
│ │ ├── inflections.rb
│ │ ├── mime_types.rb
│ │ └── wrap_parameters.rb
│ ├── locales
│ │ └── en.yml
│ ├── master.key
│ ├── puma.rb
│ ├── routes.rb
│ ├── spring.rb
│ └── storage.yml
├── config.ru
├── db
│ └── seeds.rb
├── Gemfile
├── Gemfile.lock
├── lib
│ ├── assets
│ └── tasks
├── log
├── package.json
├── public
│ ├── 404.html
│ ├── 422.html
│ ├── 500.html
│ ├── apple-touch-icon.png
│ ├── apple-touch-icon-precomposed.png
│ ├── favicon.ico
│ └── robots.txt
├── Rakefile
├── README.md
├── storage
├── test
│ ├── application_system_test_case.rb
│ ├── controllers
│ ├── fixtures
│ │ └── files
│ ├── helpers
│ ├── integration
│ ├── mailers
│ ├── models
│ ├── system
│ └── test_helper.rb
├── tmp
│ ├── cache
│ │ └── assets
│ └── storage
└── vendor
45 directories, 61 files
Let us take a look at each directory and its purpose:
app
The app directory contains models, views and controllers along with core functionality.
bin
The bin directory contains built in Rails tasks. These are executable applications that you can use to interact with your app.
config
The config directory contains environment, app, keybase and routes configurations. This is where you will go to make changes or additions to your routes via the routes.rb file.
db
The db directory contains the database schema, seeds, migrations and any other database-related files.
lib
The lib directory contains custom rake tasks as well as application specific libraries. This is where custom code that does not belong in controllers, models, or helpers live.
log
The log directory stores logs for your application. This is great for debugging!
public
The public directory contains robots.txt, custom error pages, etc. for your application.
test
The test directory contains specs, test helpers, test directories, etc. for testing your application.
tmp
The tmp directory contains temporary files. Similar to /tmp directory on Unix systems. Files stored here will not persist as expected!
vendor
This directory stores third party code. Basically anything you did not write.
Gemfile
The Gemfile file contains all application gems.
Gemfile.lock
The Gemfile.lock file contains gem dependencies and should never be modified! It is a snapshot of all gem versions for your application.
README.md
The README.md file contains documentation for your application.
Functionality
Now that we have generated a skeleton for our Rails application, let us add some functionality.
Rails provides us with many options to generate configuration. However, there are some you should avoid in order to keep a clean codebase.
rails generate controller NAME_OF_CONTROLLER ATTRIBUTESrails generate scaffold NAME ATTRIBUTESIn most cases you may not want to run the two commands above.[2] Unlike other options rails g controller will create a controller based on the model/controller name given along with all specified (optional) attributes.
It is extremely important your controller name be plural. For example, if you are building a website and require a Post controller then you should name your controller Posts and not Post![3]
So let us do that:
rails g controller Posts
Here is our output:
create app/controllers/posts_controller.rb
invoke erb
create app/views/posts
invoke test_unit
create test/controllers/posts_controller_test.rb
invoke helper
create app/helpers/posts_helper.rb
invoke test_unit
invoke assets
invoke coffee
create app/assets/javascripts/posts.coffee
invoke scss
create app/assets/stylesheets/posts.scss
Rails generated the Posts controller which included the creation of the Posts views for sharing data with the controller.
./app/controllers and ./app/views are the only two directories in this generation that concern us at the moment.
RESTful functions
Most (good) web applications on the Internet make use of CRUD functionality. That is CREATE, READ, UPDATE and DELETE which originated from database records. Data is created, read or accessed, updated by the user and can also be deleted. Think of this in terms of creating or editing a post on a social network. Except Twitter because you cannot edit (UPDATE) Tweets. So in this case I believe Twitter makes use of CRD functionality?
Rails' routing system combines verbs and URL patterns to route a user to a specific webpage depending on the request. When a user is routed to a page the process of CRUD takes place.[4] This system is the foundation of REST which stands for Representational State Transfer that is an architectural style on how to develop web services. [5]
Rails recognizes requests and sends them to a controller's action. It also generates paths and URLs so we can avoid hardcoding them in our application which is not recommended. When we generated our controller above, we optionally could have specifed RESTful functions to be used.
rails g controller Posts index show new create edit update
Omitting those attributes provided us with an empty routes.rb file which is where we define these functions in our application. Specifically in ./config/routes.rb
This would have also generated the associated views for each RESTful function used in our Posts controller:
app/views/posts/
├── create.html.erb
├── edit.html.erb
├── index.html.erb
├── new.html.erb
├── show.html.erb
└── update.html.erb
To manually configure our routes, we have to edit the ./config/routes.rb file, listing the ones we need in our application:
get 'posts/:id/edit', to: 'posts#edit'
This maps the request for posts/:id/edit to a controller action in the posts controller.
For example, if you navigate or access a web page who's URL is http://example.org/posts/:1/edit you would be directed to an edit page for that specific resource. With our current dynamic configuration we can avoid hardcoding or using a static path that will always map to the same request.
This is why the id portion of posts/:id/edit is important as it makes this possible (dynamic).
We optionally could define our routes using Resource routing:
resources :posts, only: [:index, :show, :new, :create, :edit, :update]
or
resources :posts, only: %i[index show new create edit update]
as my linter recommends (to avoid using :symbols).
This will create 6 routes for our Posts model.
If we ran rake routes in our terminal we'd see the following:

As you can see the routes were generated as result of our ./config/routes.rb file .
rake routes returns the full list of rails routes.
On the left we have the path prefix or helper, then our HTTP methods and the URI pattern or path to access each action. We then are given on the right a view of the controller and action name for our model. Since we have created a Post model, our controller name will always be posts as mentioned previously. Each prefix is mapped to a controller action. So if we wanted to edit a post /posts/:id/edit we would define the action in our edit method in the posts controller as such:
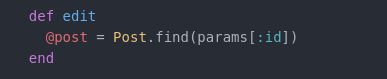
This is saying for the requested post get us that page. params (parameters) originate from the user's browser when the page (or resource) is requested.
For example: http://example.org/posts/2/edit would request the edit page for post number 2.[6]
Our path prefixes are important because they save us time and are efficient. When we make use of action view form helpers such as link_to, form_tag, form_for, etc. we will need to specify paths for different actions. If we simply use the path prefixes such as new_post, edit_post, etc.[7] instead of hardcoding the path then we can avoid having to manually change the routes as things change over time. In this way we would only be making one modification and will not unintentionally break (HTTP 404) pages.
But what would happen if we simply did this?
resources :posts

We then get all 7 RESTful routes! Or in the case of this post title, the 7 RESTFUL things!
If the web application we are developing is not a Twitter [8] clone and makes use of all routes then there is no need to specify the routes manually. We can just use resources keyword. There are also custom actions we could define in our ./config/routes.rb such as named routes.[9]
What "the things" do
To make use of CRUD operations, we have to use specific HTTP methods for each action we want to utilize. These are the RESTful routes discussed above.
GET
The GET request retrieves a resource only.
It is one of the most common requests you will see on the Internet.
In our example routes above, our first route:

makes use of GET to retrieve the index resource which is the hompeage of our application. For example, if we navigate to http://example.org/posts we will see the contents of the post controller's index action which of course is defined in the ./app/controllers/posts_controller.rb file and whose view (webpage) is located at ./app/views/posts/index.html.erb.
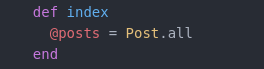
This defines an @posts instance variable (available to all methods) which gives us all records in our Post model.
POST
Unlike GET, POST creates a new resource.
In the example of our rails routes, the user makes a GET request to new action in our posts controller .

This will retrieve the webpage to create a new post that when submitted will inititate the POST request, creating that post.

Our ./app/controllers/posts_controller.rb file contains the code for both actions in their identical methods.
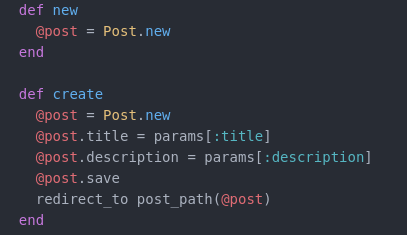
The new method (mapped to the new action as displayed in rails routes) renders a form to create a new post[10]as defined in our posts controller file.
Our URI in this example is /posts/new (http://example.org/posts/new)
A POST request to /posts (http://example.org/posts/) takes the created record from our new action above and passes it to the create action in our posts controller and stores it in the database.
PUT
A PUT request updates an existing resource.
In our rails routes output, the user makes a request to a post. This action like all others is defined in our posts controller file.

In order to update an existing resource, we must access it.
Our routes define where the request is passed.

Our URI in this example would then be /posts/:id/edit where id is the specific post we want to modify.
For example: http://example.org/posts/2/edit
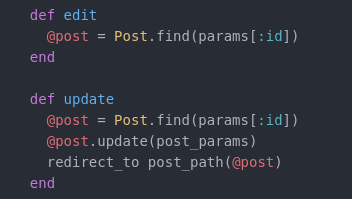
The edit action finds the post we are looking for via the post id and renders the form to modify it.
Our update method or action actually does the work by updating the post in our database which in this case will redirect us to the post page displaying the changes made to that post specifically.
DELETE
A DELETE request deletes or removes a resource.
We can view this request in our routes:

The example request URI is /posts/:id where we are accessing a specific post that we want to remove.
This is defined in the destroy action of our posts controller:
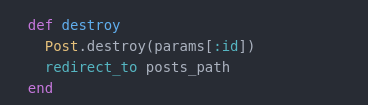
Here we are calling the destroy method[11] on our Post model and finding the post by id via params. We then redirect the user using the posts_path route helper[12].
PATCH
PATCH requests are used to make minimal updates on resources.
If we are not replacing the whole resource (PUT) then this is the request to make.

This request is also defined in our update action such as in our PUT request.
The difference between PUT and PATCH
PUT and PATCH request are quite different. This may be confusing. PATCH requests are used to make partial changes only. If we are updating a single post in the case of our example then a PATCH request makes more sense. However, if we are replacing all posts then a PUT request is the call to make.
Based on documentation it seems both exist to reduce overhead. There is little work to be done if you are just replacing a single resource. For example, in the case a PATCH request is made comparing the update against the original (diff) and only applying the changes. Whereas, a PUT request updates the whole resource. It does not care about what has changed. It replaces everything.
In a PUT request, the enclosed entity is considered to be a modified version of the resource stored on the origin server, and the client is requesting that the stored version be replaced. With PATCH, however, the enclosed entity contains a set of instructions describing how a resource currently residing on the origin server should be modified to produce a new version.[13]
There are also more HTTP methods such as HEAD, CONNECT and OPTIONS but I will not discuss them in this post. [14]
There are so many methods and resources to implement when building a modern web application using Rails. But familiarity with some RESTful APIs is one of the core fundamentals to consider. Of course not everything was covered in this post and I encourage you to read "all the things" for more information.
1. https://danielmiessler.com/study/url-uri/
I also highly recommend this blog!
2. rails generate scaffold will generate most of your application (models, views, controllers, etc). However, there are pieces that you may not need and their existence would pose performance/security issues for your application if they're dormant. It is recommended to only create or generate the pieces that you need unless you've a reason to actually use scaffold. https://qiita.com/Kolosek/items/697ad33bb82932ebed73/
3. https://guides.rubyonrails.org/getting_started.html#generating-a-controller
4. https://https://guides.rubyonrails.org/routing.html
5. https://www.ics.uci.edu/~fielding/pubs/dissertation/top.htm
6. https://flatironschool.com/blog/how-params-works-in-rails/
7. https://guides.rubyonrails.org/form_helpers.html
Also, see:
https://api.rubyonrails.org/classes/ActionController/Helpers.html
8. https://developer.twitter.com/en/docs/api-reference-index.html
9. https://stackoverflow.com/questions/14188691/rails-tutorial-named-routes
10. By the way, these forms are usually created and stored in ./app/views/model_name/form_name.html.erb https://guides.rubyonrails.org/layouts_and_rendering.html
11. https://apidock.com/rails/ActiveRecord/Relation/destroy
12. See the source-code for how this is defined: https://github.com/rails/rails/blob/master/actionpack/lib/action_dispatch/routing/route_set.rb#L127
13. https://tools.ietf.org/html/rfc5789
14. https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods